假設有另一個 Estimator ,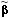 ,它是一個任意( Arbitrary )的 Linear Estimator 。
,它是一個任意( Arbitrary )的 Linear Estimator 。
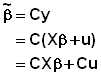
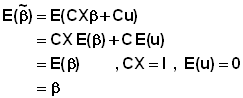
它是一個沒有偏差 ( Unbiased ) 的 Estimator 。
是時候入戲肉了,
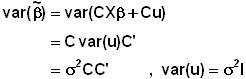
C = ( X' X )-1 X' + D
CX = I => ( X' X )-1 X' X + DX = I
=> I + DX = I
=> DX = 0
CC' = [( X' X )-1 X' + D]' [( X' X )-1 X' + D]
= ( X' X )-1 X' X ( X' X )-1 + DD' , DX = 0 , X' D' = 0
CC' = ( X' X )-1 + DD'
如果 DD' 是正數( Positive SemiDefinite , PSD ),DD' ≧ 0 ,那麼
由此推斷,透過 LS 找出來的 Estimator ,它的 Variance 是所有 Estimator 中最細,因而稱它為最好、最有效率( Best ) 。




